Perlucidus Software Project Survey
Progress to Date
Since the last time I wrote about the this software project transparency survey a lot has been accomplished:- I’ve refined the survey in several ways, and added new data that is used to define how the server handles questions, when they are skipped, and what the valid answers are.
- I’ve created a dynamic survey engine on an AWS server based on templates created by RapidWeaver. The survey tool supports resuming at a later time so someone doesn’t have to finish the survey all in one sitting. Yet, it maintains anonymity. :-)
- I’ve created an initial web-based console that allows me to see how many surveys have been submitted, how many are in progress and how far they have gotten on average. It is the platform on which I’ll generate reports to show correlations or the lack thereof.
- I’ve implemented a review mode so I can invite people to review the questions. The console tool allows me to see the comments made. This won’t be part of the final survey that people will fill out. It is there to allow collaboration with others before the survey is put into use with non-reviewer participants.
- I’ve chosen a name for this project: Perlucidus Software Project Survey. In fact, I already owned the domain name perlucidus.info so I’ve been using that as the home domain for this project.
I like the idea of information itself being like a perlucidus cloud:Perlucidus clouds refer to cloud formations appearing in extensive patches or layers with distinct small gaps in between the cloud elements to allow higher clouds, blue sky, sun or moon to be seen through the gaps.
- In a location where everyone can see it
- It doesn’t eclipse other things but coexists with them in a way where more can be added and all can still be seen
- Is lightweight and doesn’t dominate the reality on the ground
And so, on my perlucidus.info AWS server I created the beginnings of the Perlucidus Software Project Survey. And, here is the review version of that web site, configured for review:
What’s next is a review of the questions themselves. I will reach out to some of my software engineer friends to help review this survey and offer feedback for improvement. Anyone is welcome to offer comments. The survey is completely anonymous, so if you want me to know who you are you will have to put your name inside of one of the review comments. Otherwise, I’ll take your comments as anonymous comments. The only downside to anonymous comments is that if I have any kind of followup question about your comments, I won’t know who to ask.
Research on Transparency in Software Projects
Throughout my development of the software and the survey data, Dr. Jennifer Rice has been thoughtfully helping me to understand how to collect useful data. Collecting data won’t be nearly as difficult as collecting useful data. The difference has everything to do with whether participants can understand a question well enough to answer it, or whether the question is flawed in some way so that the user ends up answering a question that wasn’t actually being asked. Dr. Rice provided graduate-level books and advice and example questions and encouragement and criticism and patience.Dr. Rice has also been researching published papers on related topics. One goal of that research was to find out if it was even necessary for us to proceed. If the data already exists, there may be no need. But, her search revealed nothing that would suggest our survey is redundant. Another goal of that research was to determine how other researchers have approached similar problems. She found over a dozen papers on various topics the had useful examples or methodologies or analyses. She pointed out how extensive the methodology sections of some of these papers were and suggested that for this kind of research there didn’t seem to be established standard practices (aside from practices that apply to all kinds of survey-based research).
There are other transparency-related academic papers; however, their use of the term “Transparency” has more to do with organizational style than information sharing practices as far as I can tell. Here are some examples:
- Multi-method analysis of transparency in social media practices: Survey, interviews and content analysis. (Marcia W. DiStaso, Denise Sevick Bortree, 2012)
- Organizational Transparency and Sense-Making: The Case of Northern Rock (Oana Brindusa Albu & Stefan Wehmeier, 2014)
- Organizational transparency drives company performance (Erik Berggren and Rob Bernshteyn, 2007)
- Radical transparency: Open access as a key concept in wiki pedagogy
The purpose of this article is to argue that we need to extend our understanding of transparency as a pedagogical concept if we want to use these open, global wiki communities in an educational setting.
- Radical Transparency? (Clare Birchall, 2014)
This article considers the cultural positioning of transparency as a superior form of disclosure through a comparative analysis with other forms.
Details on using RapidWeaver with Perl CGI
The survey generation based on spreadsheet data is accomplished like this: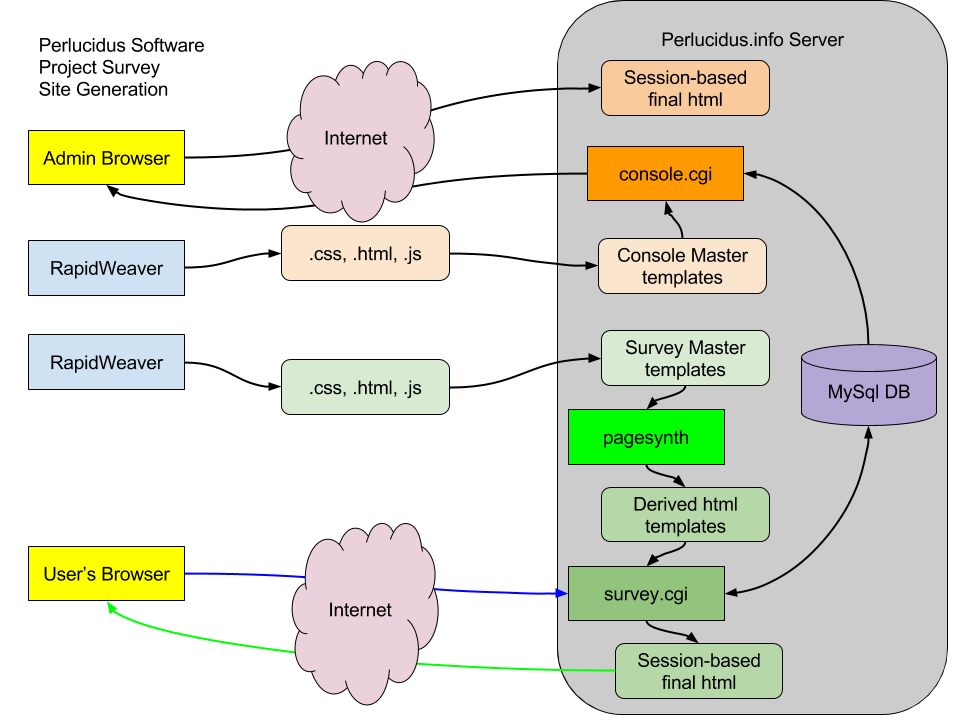
(Click image to see it full-size)
RapidWeaver produces .html, .css and .js files which I copy to the server. A tool called pagesynth (bright green box) converts the pages by processing macros in the templates that themselves are ignored by RapidWeaver. The macros add navigation, context about each question, review fields and more. The parts of the page that a dynamic web site would produce are produced by pagesynth, once, when the survey is initialized on the server. After that, the database and CGI are not involved in building those aspects of the page, which takes a big load off the server and improves performance for the user.
The result of pagesynth is a set of “Derived html templates” which are read in by survey.cgi. Survey.cgi expands a second set of macros (that are not recognized by RapidWeaver nor pagesynth). Those macros can only be expanded at runtime as they include the user’s session number. Survey.cgi reads in the template and resolves those last-minute values and includes them in the web page seen by the participant. It also records the answer if they submitted one. Survey.cgi also handles resuming the survey, and sending a link via email so a participant can resume.
A transparent project on transparency?
Since my last blog post I’ve made some good progress on a set of survey questions (see the “Two Projects” tab) and also on understanding the overall lifecycle of this project. I’m grateful for the help of Dr. Jennifer Rice. As I was pondering how helpful she has been it occurred to me that I didn’t actually know what I’m asking her to do. And, I also wasn’t very sure of what I was asking me to do, and while I’ve done some work, I didn’t really know what was next. So I set out to draw a picture of the project that would show a sequence of events, dependencies among them, and where I would need outside input. It ended looking like this:
![]()
(Click image to see it full-size)
(Click this for the latest version)
The diagram shows that I’ve created a survey, revised it for Bias and Loading and revised it for consistency. Dr. Rice is currently reviewing it. Then I’ll open it up to friends and interested parties for their feedback, after which I plan to revise it again to take their comments into account. After that the survey needs the approval of an Institutional Review Board whose job it is to oversee research involving human subjects, Dr. Rice explained to me. Many concepts seem analogous to the steps I take as a programmer when creating an e-commerce or even HIPAA-compliant system: protect people’s identity and privacy, don’t collect personal information you don’t need, etc. In the diagram that is the “IRB Approval ?” step. It is iterative because the IRB will make recommendations that need to be factored into the project somehow, or may need further explanation. When they are satisfied we can begin testing the survey by asking people to fill it out.
Simultaneously with the development of the survey, I have begun working on three instruments. They are “Scorecards” only in a colloquial sense, but that is what I call them. These instruments are each derived from a subset of the questions in the survey. All of the questions related to Gauging Transparency ended up in the Software Project Transparency Scorecard. All of the questions related to Personal Outcome will end up in the Personal Outcome Scorecard. Similarly there will be a Project Outcome Scorecard. I’ve only worked on the first one, but it will likely be the largest.
The scorecards provide a value for each possible answer to each question included in them. There is also often one or more disqualifying responses and these are give a nil value that will not affect correlations, averages, etc. Most questions are of the type “Never, Rarely, Sometimes, Often, Always,” but sometimes Always is best and sometimes Never is best. Other questions have their own unique set of choices.
As a start, I have assigned consistent but arbitrary coefficients for every single response to every single question in the scorecard. This is an uninformed scorecard. That is, it might ask the right questions, but it doesn’t apply weight to the answers with any insight into which responses are actually more important than others, nor how much more important.
One goal of the survey is to shed light on how transparency practices correlate with outcomes. Specifically, to understand which ones seem correlated with better outcomes, and which ones do not seem to be. I think the scorecard can be improved and made less arbitrary in a few ways:
1. Questions that have no significant correlation should be dropped from the scorecard
2. Questions that have a strong correlation should get a higher coefficient as a result. How much higher could be driven by the strength of the correlation, when compared to the strength of the other correlations.
3. Questions which correlate strongly with each other, but are not equivalent in what they are asking, define a subset of practices of interest.
At the moment, with these arbitrary coefficients, the Software Project Transparency Scorecard is informed by 81 different questions. The worst score is -128 and the best score is +152. As I mentioned, this is with arbitrary coefficients. The number of questions included and the coefficients will change based on data derived from survey responses.
After the survey responses have been used to tune the scorecards, I think it would be possible to build a CGI tool that asked a series of questions and then used the answers to make some conditional recommendations. For example: If you are seeing a problem with X, these practices have been correlated with projects that saw less X. That way if someone isn’t seeing a problem with X, even though their responses correlate with people who did, in their project that isn’t a problem. I don’t think this survey can show causality, so the strongest suggestion we can make is that there is a correlation and if there’s a problem perceived, these might be things to consider. Not cause and effect: there are no guarantees. The goal is to propose relevant questions to consider.
![]()
(Click image to see it full-size)
(Click this for the latest version)
Understanding the link between Transparency and Sexism in Software Projects
I am now firmly convinced that the primary mechanism by which women have been systematically excluded from the software industry is lack of transparency in software projects. It is all just my opinion, so please forgive me for not making this 10% longer by adding "I think" and "I believe" in front of every statement:
Software is information that is understood best by its creators and it is up to them whether and how to share that understanding.
Software engineers are rewarded for their productivity and not the productivity of others who need what they know.
Male software engineers treat instances of female engineers seeking the understanding they'd need to succeed as an opportunity for *something other than learning*, but they *don't behave the same way with male engineers*.
The result of the bias in gender-related behavior creates circumstances that impede a woman's opportunity to learn safely. When the currency is information and understanding that information, it is obvious to me that women are systematically made poor by a system that at its core comes down to allowing the worst characteristics of men to have more influence than they should. The way to *neuter* this problem is to ensure that information and understanding are made transparent and equally accessible. The only way to do that is to change the fundamental value system applied to software engineers: if you don't document your code, you are a bottom performer. If you don't write clearly what you have done so that competent engineers can understand it, you've done an incomplete and perhaps poor job. So long as managers care only about features/day regardless of how anyone else might be able to learn about and support those features in the code, the managers are by complex effect victimizing women by essentially empowering their male peers to use extortion if they wish for the same information that should have been required. Software created without transparency guarantees women will be second class citizens in my industry.I care deeply about this issue. I've written as much documentation as code in my life, so I've walked the walk of software transparency. You might not know it, but I created this site: http://www.transparentsoftware.orgYes, it begins with a quote from MLK, because I think he would have liked his granddaughters to be software engineers if they had a desire to, and the state of the industry at the moment is in its own way as unbalanced as civil rights laws were in his day. Except that then it was clear what the problem was and people didn't agree on how to deal with the problem. Today it seems people don't understand why women are at such a huge disadvantage in the software industry, so in fact, we have very, very long way to march before we all come together on *why* this is happening, so that together we can bring this industrial bias to an end.
To be fair, these are the words of a layman with a lot of experience, but still a layman: me. My friend, “Jesus Mathew” (his nickname), pointed out that, “The plural of anecdote is not data.” I agree.
But, I nonetheless believe this (as of writing) and would like to understand whether it is true or not. To that end I began work on a survey that might have the potential to show with data what I believe to be true. This is challenging for me because:
- I have never earned a PHD or Masters degree in social science, so I know practically nothing about how to collect this kind of data in a way that would be considered valid for research and analysis. In fact, I was abysmally poor at social science in school. I’ve since gained both appreciation and some experience in it.
- What kind of a survey could adequately express transparency in a software project and how could that be related to sexism, and also to racism and other forms of social injustice it might affect?
- How could I collect enough information to notice meaningful correlations?
- Could enough data be collected so that a causal link could be shown? Or is correlation the best I can hope for?
These questions seemed daunting to me, but Jesus is right. Without some data to back up my belief, it is relegated to being only a belief. Such a belief cannot really help many people because it is only a belief.
A healthy discussion followed my posting on Facebook and through that I decided to attempt to collect data and publish it if possible for others to use. Jesus suggested PLOS. I am committed to publishing in a way that anyone can access not only the results of the research, but also the survey data itself. If the data is useful for my purposes, I believe it would also be useful for other purposes. And, in any case, there are a lot of ways to analyze the same data and it isn’t all going to occur to me.
I also gained a collaboration partner through that thread, Dr. Jennifer Rice, who has a PHD in health services and policy analysis. She earned her PHD from UC Berkeley in 2015. She’s both brilliant and experienced in how to run a social science survey, and she understands quite a bit about technology too.
I began work that day in a Google Sheet with world-read permissions, but write permission for myself and Dr. Rice. The sheet is here:
Inside the sheet I first made an attempt to write down every question I could think of relating to software project transparency and how sexism might intersect it. In a few hours I had over 100 questions, but that seemed like too many (See the tab called “Possible Questions”. I attempted to refine them by prioritizing them and eliminating the lower priority ones and produced the tab called “Filtered Questions” and then I grouped them and “factored” them, by which I mean extracting a common predicate such as “How frequently did this occur:” and grouping all questions with common predicates together. The result was the “Grouped and Refactored” tab. When I was done with that process, I looked at the results and was disappointed. The culling by priority had, in my opinion, damaged the survey by eliminating less important questions that were either going to be used as a control, or to eliminate ambiguity, or to provide some redundancy for points that might need it. While it was shorter, I feared it had died on the operating table of efficiency.
Then I met with Dr. Rice about the survey and she helped me understand some of the weaknesses in my approach. She gave me two books filled with bookmarks for important sections:
- Research Methods for Community Health and Welfare, by Karl E. Bauman.
- Approaches to Social Research, by Royce A. Singleton, Jr., and Bruce C. Straits.
I read the sections she pointed to and learned that my original questions suffered variously from bias and loading. A survey full of biased, loaded questions is exactly the kind “research” that is disingenuous and unhelpful. It would do more to discredit what I am trying to show than to support it. Also, it became obvious that the kinds of questions I was asking were not going to be that helpful. They were mostly of the form of, “In your entire career, how often has xyz happened to you?” These kinds of questions are very difficult to answer accurately, and they take a lot of thinking about each one. Of course, if we could collect that data it might possibly be useful, but the difficulty of collecting accurate data that way seemed like a nonstarter after talking with Dr. Rice. Furthermore, since we didn’t know which projects were run transparently and which were not, and any answer could apply to any project, correlations would be dubious at best. It seemed to me that the original survey was unusable.
Some time passed while I considered this. I decided that a better approach would be to come up with a set of questions, and then ask people those questions about two projects they had worked on. That would make it possible to compare answers a person had given to identical questions about the other project. But, which two projects? I’d love to ask them to answer about the “most transparent project” they’ve worked on compared to the “least transparent project”, but in fact, I’m specifically not using the word “Transparent” or “Transparency” in any of the survey questions or their enumerated responses. I don’t believe the word “Transparency” is widely used with respect to software projects. I didn’t want to confuse matters by relying on whether people might understand the concept of software project transparency.
I created a new tab called “Two Projects” and I copied in my original list of questions and grouped and refactored them. Then I went trough the question list and assessed on a scale of 1 (least) to 5 (most) how biased or loaded each question was. I reworded questions to reduce bias or loading however I could. My goal was to achieve mostly 1s and 2s and in the worst cases 3s. It is difficult to ask someone if they wrote documentation while on a software project without implying that writing documentation might be a good thing and if you didn’t do it you or your project are somehow lacking. It is difficult to ask someone if they felt afraid to ask someone else a question without creating the impression that they might be weak. The survey questions delve not only into how companies are or are not transparent, but also how individual actions support transparency or not. It is in this later area that it is difficult to avoid loaded questions. The danger is that people want to feel good about themselves and may answer in ways that make them look good or feel good, rather than answering honestly.
In the same pass I also assessed how complex the question was. I call this “cognitive load” but really, what I mean is “how likely is it that someone will misunderstand this question?” Also, it is my opinion (fear) that increased cognitive load in questions reduces enthusiasm for finishing the survey. I rated questions from 1 (least chance to misunderstand) to 5 (most chance to misunderstand). Any question that was a 3 or worse probably needed to be reworded or split into multiple questions. This increased the number of questions only slightly, but the reduction in complexity and bias was essential.
The result is a survey that I think has the potential to reveal the relationship between transparency in software projects and sexism, racism and undesirable stratification among team members.
I think the next steps include:
- Finishing the bias/loading/complexity assessment and refinement of questions
- Engage a few people to take the survey to find flaws, opportunities for improvement, and to find out how long takes to complete.
This is an ongoing effort and I’ll make additional blog entries as I make more progress. I am excited to be working on something that might possibly help level the playing field in the software industry. While the title of the worksheet mentions sexism, I think this applies to more than just sexism. Dr. Rice suggested expanding the questions about the participants so we can use the same analysis to understand if people of color, women of color, or other sub-groupings are also negatively affected by a lack of transparency in software projects. I honestly can’t see how it could be true for sexism and not be true for some of these other groups.